
Part 1 of Three-Part Series on Data Privacy in Production AI
If you've built an AI agent that handles customer data, you've probably already had the conversation:
Should we mask this before logging?
Do we need to encrypt everything?
How do we anonymize training data without losing context?
The honest answer is: it depends on the field, the use case, and where that data flows. One-size-fits-all privacy doesn't work for agentic AI.
I've been building privacy infrastructure for production AI workflows at FlowGenX AI for the past few months, and I keep seeing the same pattern: engineering teams treating privacy like a checkbox exercise, applying traditional tools that were designed for batch ETL pipelines, not real-time agent workflows. Then they discover—usually the hard way—that those tools don't work when your AI is continuously processing, routing, and transforming data across multiple touchpoints.
This is Part 1 of a three-part series where I'll share what we learned. In this post, I'll show you why traditional privacy approaches break for agentic AI and where most teams are unknowingly leaking customer data.
The Wake-Up Call Nobody Wants
Last month, a Fortune 500 company's AI customer service agent inadvertently logged 47,000 customer email addresses in plaintext. The breach? An observability tool that was "just for internal monitoring." The fine? Still being calculated. The lost trust? Immeasurable.
This wasn't a hack. It wasn't a sophisticated attack. It was a normal AI agent doing normal things—processing customer queries, logging interactions for debugging, storing context for follow-up conversations. The privacy controls were there, technically. They just weren't designed for how AI agents actually work.
According to recent industry surveys, 87% of enterprises are actively deploying agentic AI, but only 31% have implemented real-time privacy controls that work across their agent workflows.
The Fundamental Difference: Continuous vs. Point-in-Time
Traditional data privacy tools were built for batch processing—ETL pipelines that apply privacy once and you're done.
Traditional ETL pipeline:
- Extract data from source
- Apply privacy transformations
- Load into destination
- Done.
AI agent lifecycle:
- Customer query arrives with PII
- Agent processes query (logs? metrics? observability?)
- Agent fetches context from databases
- Agent makes real-time decision
- Agent responds to customer
- Agent stores interaction for training
- Agent triggers downstream workflows
- Repeat indefinitely
Your agent doesn't process data once—it continuously routes, transforms, and exposes information across multiple touchpoints. Traditional privacy tools are "bolt-on" solutions—separate services you call before or after processing. By the time you realize you need to mask that email address, it's already been logged by your observability stack, cached in your vector database, and embedded in your training data.
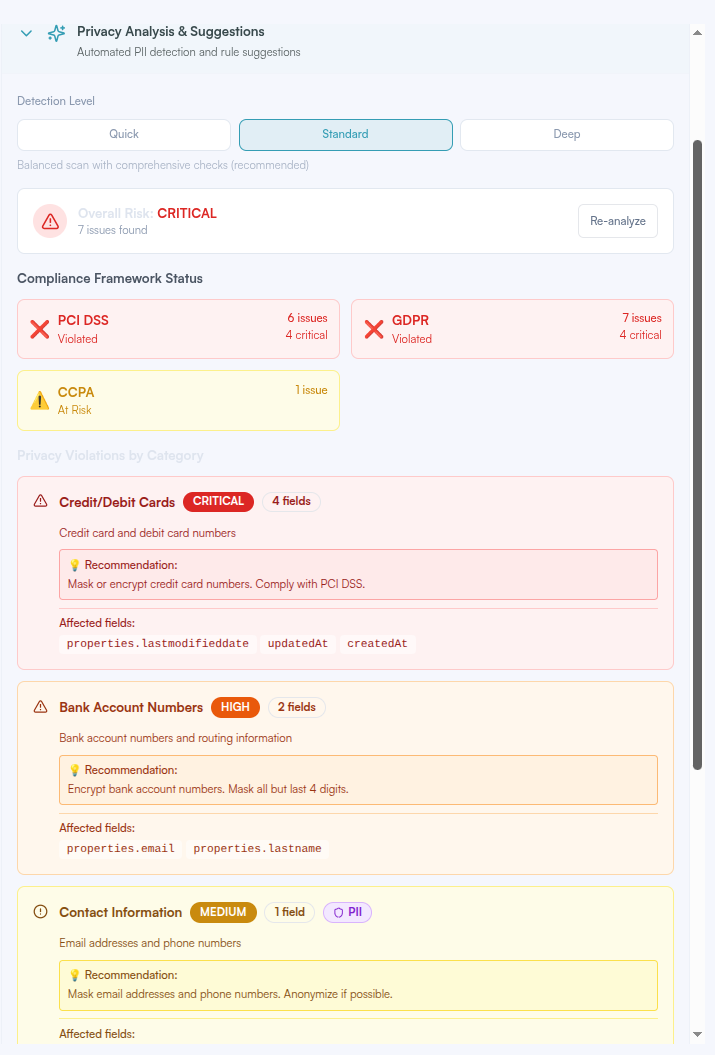
The Three Blind Spots Where PII Leaks
When we audit AI agent workflows, we consistently find PII leaking in these places:
Blind Spot #1: Observability and Monitoring
Your logging platform is capturing full request/response payloads. Customer emails, phone numbers, and account IDs are sitting in logs accessible to your entire engineering team—retained for 30-90 days.
Real example: A healthcare AI startup logged doctor-patient conversations for debugging. They had 60 days of HIPAA violations sitting in CloudWatch before they realized it.
Blind Spot #2: Vector Databases
You're storing customer conversations in your vector database for context retrieval. The embeddings contain semantic meaning—including the PII. When you share these with data science teams or third-party vendors, you're sharing sensitive information encoded in vector space.
Real example: A financial services company's ML team could query their vector database and reconstruct customer account numbers from nearest neighbors.
Blind Spot #3: Training Data Exports
You're exporting conversation logs to improve your AI model without proper anonymization. When that data crosses borders or gets shared with contractors, you may be violating GDPR, HIPAA, or customer DPAs.
Real example: A SaaS company exported 6 months of chat logs to S3 for an offshore ML team, unknowingly violating enterprise customers' Data Processing Agreements.
Why "Just Anonymize Everything" Doesn't Work
The obvious solution seems simple: anonymize all data before it enters your system. But this creates three new problems:
Problem #1: Different stages need different protection
Your customer service dashboard needs ****-****-****-1234 so reps can verify card ownership. Your compliance team needs full encrypted values with audit trails. Your ML team needs realistic-but-fake data that preserves patterns. You can't pick one approach for all use cases.
Problem #2: Speed matters
Adding 500ms of anonymization latency to real-time customer responses is unacceptable. But for overnight training exports, you can afford thorough protection. Different touchpoints have different performance requirements.
Problem #3: Consistency breaks
If "Dr. Sarah Chen" appears in 47 patient notes but becomes "Dr. Alice Smith" in note 1, "Dr. Bob Johnson" in note 2, and "Dr. Carol Williams" in note 3, you've destroyed analytical value. Researchers can't track patient journeys when the same doctor becomes different people in every note.
This is entity-level consistency, and most traditional privacy tools don't support it.
What Modern Privacy Requires
Building trustworthy AI agents requires rethinking privacy as a workflow-native capability, not a separate service.
1. Privacy by Stage, Not by Dataset
Different stages need different methods:
- Input validation: Fast masking (<1ms) to prevent PII in logs
- State storage: Encryption (<10ms) for compliance and audit trails
- LLM API calls: Smart masking to prevent leaking to third parties
- Training exports: Irreversible anonymization (100-500ms) with entity consistency
- Analytics: Aggregation that preserves insights while removing identifiability
2. Entity-Level Consistency
When you anonymize data, the same entity must become the same fake replacement everywhere—across your entire workflow, not just within a single document. If "john.doe@company.com" appears in 3 contexts, it should become "michael.brown@example.org" in all 3 places.
3. Observable and Auditable
Compliance isn't just about protecting data—it's proving you protected it. You need audit logs that capture what was protected, when, how, who triggered it, and the result status. This audit trail is what regulators ask for.
The Business Case
Privacy is becoming a competitive advantage, not just a compliance checkbox.
Companies that get privacy right:
- Build customer trust (transparent data handling)
- Move faster (no post-breach scrambling)
- Enable new use cases (data sharing, cross-border operations, ML training)
- Reduce compliance risk (proactive protection, auditable)
Companies that don't:
- Face regulatory fines (GDPR fines average €2.5M per violation)
- Lose customers (67% would switch providers after a breach)
- Limit AI capabilities (can't use sensitive data for training)
- Waste engineering time (months cleaning up breaches)
Your Action Items This Week
1. Map One Data Journey
Pick a single AI agent workflow. Trace one piece of PII (like a customer email) through the entire system: where it enters, transforms, stores, transmits, and exposes. You'll likely find 2-3 leakage points you weren't aware of.
2. Audit Your Observability Stack
Check what your logging tools are capturing. Are they logging full request/response payloads? This is often the biggest blind spot.
3. Ask Your Vendors the Right Questions
If you're evaluating AI platforms, ask:
- How do you handle PII in real-time workflows?
- Can I apply different privacy methods at different stages?
- Do you maintain entity consistency across anonymization?
- Can I audit what data was protected and how?
If they don't have good answers, that's a red flag.
Take the Next Step
Ready to see FlowGenX in action? Click on Request a Demo on top of this page and discover how our intelligent automation platform can help your team cut response times, boost ROI, and deliver next-level customer experiences.
Continue reading: In Part 2, I'll walk you through the three privacy methods that actually work for agent workflows—smart masking, field-level encryption, and intelligent anonymization—and give you a decision framework for choosing the right method for each use case.
Building AI agents? We built FlowGenX to make privacy-first agentic AI the default, not an afterthought. Learn more about our approach to workflow-native data protection.
Join the conversation with your LinkedIn or Google account